![]()
Быстрая навигация
Собрать данные — это только начало. Можно до бесконечности заполнять таблицы, но какой смысл, если эти данные просто лежат мертвым грузом? Регрессия — мощный статистический инструмент, который помогает находить реальные зависимости. А с Python этот процесс становится элементарным и гибким, не чета старым добрым электронным таблицам. Забудь про бумагу и карандаш — пора по-настоящему научиться извлекать смысл из цифр. Начнем с главного.
Простая линейная регрессия: обнаруживаем тренды
Базовая и самая понятная регрессия в Python — это простая линейная регрессия. Здесь мы ищем взаимосвязь между двумя переменными: одна независимая, другая — зависимая. Обычно их размещают по осям x и y, создавая классическую точечную диаграмму (scatterplot). Задача — провести через облако точек линию, которая лучше всего отражает их общую тенденцию.
Для примера возьмем чаевые в ресторанах Нью-Йорка и попробуем понять, есть ли связь между суммой счёта и размером чаевых. Такой набор данных уже встроен в Seaborn — моей любимой библиотеке для визуализации. Всё это удобно работает в окружении Mamba.
Сначала подключаю Seaborn — одну из самых простых и наглядных библиотек для статистики.
Загружаю сам датасет:
Если работаешь, как и я, в Jupyter notebook, добавь вот эту строку — и графики будут появляться прямо рядом с кодом:
Смотрим на точечную диаграмму с помощью relplot:
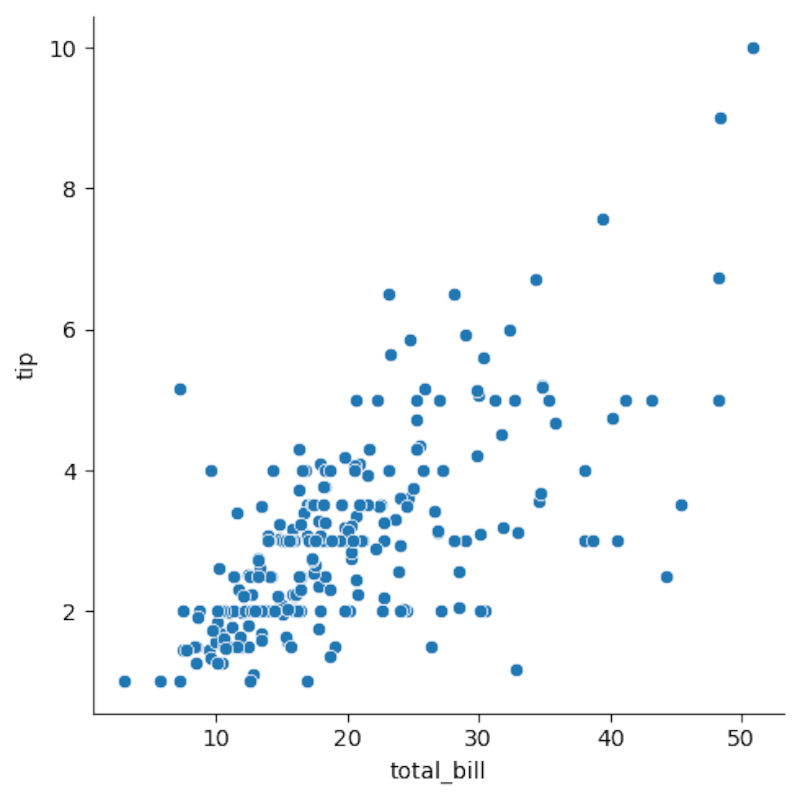
Видно, что между суммой счёта и чаевыми есть прямая: на графике линия зависимости явно линейная. Добавляю regplot — он сразу рисует линию регрессии:
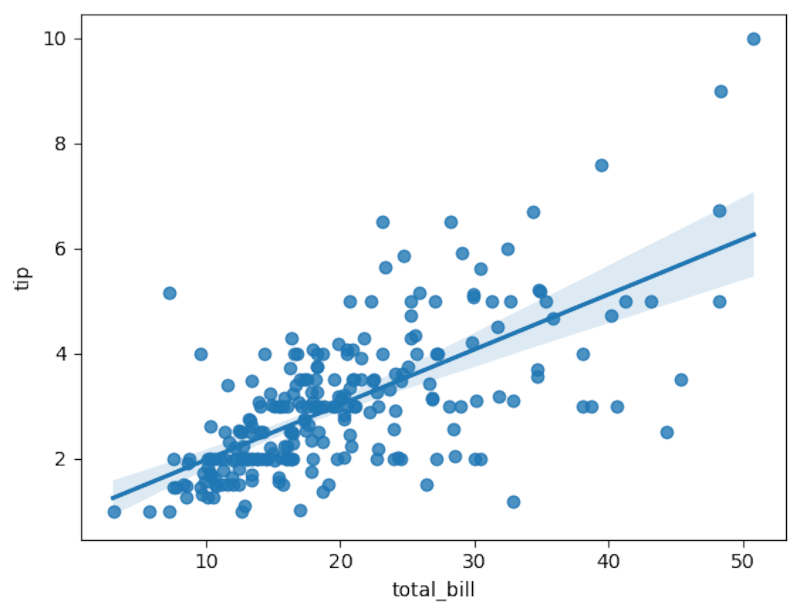
Линия регрессии отлично ложится по данным.
Для более детального анализа подключу библиотеку Pingouin. Её функция linear_regression вычисляет коэффициенты уравнения регрессии и показывает, насколько хорошо наши точки ложатся на прямую.

Коэффициент r² (в Pingouin — «r2») отвечает за силу связи между переменными. Здесь он равен 0,46 — это вполне достойно. Корень из r² — около 0,68. Почти единица, значит: чем выше счёт, тем выше чаевые. И график это подтверждает, и расчет.
На этой основе строю модель. Если помнишь уравнение прямой: y = mx b. В нашем случае: y — чаевые, x — сумма счёта, m — коэффициент (~0.11), b — y-перехват (~0.92).
Уравнение для модели такое:
В Python традиционно записывают формулу вот так:
Можно быстро написать функцию для прогноза чаевых по сумме счёта.
В Python вторая строка в функции должна идти с отступом (4 пробела). На сайте это может не отображаться, но в коде обязательно!
Например, считаю чаевые для счёта в 100 долларов (~9000 рублей):
Ожидаемый размер чаевых — примерно 12 долларов (~1080 рублей).
Множественная регрессия: зависит уже от нескольких параметров!
Линейная регрессия — это не только две переменные. Можно добавить третью, четвертую и сколько угодно. Ты уже ищешь не просто линию, а целую плоскость, которая отражает зависимость. Такое визуализировать сложнее, но результат оправдывает усилия. Например, я когда-то строил модель цены с учетом сразу нескольких характеристик.
Возьмем наш набор с чаевыми и добавим к анализу размер компании (столбец «size»). Pingouin с этим тоже справляется отлично.
Обрати внимание: при передаче нескольких переменных их нужно обернуть в двойные скобки. Интересно, что r² почти не меняется — это значит, что и сумма счёта, и размер компании хорошо предсказывают размер чаевых.
Уравнение теперь дополняем новым коэффициентом для размера компании:
Нелинейная регрессия: теперь строю сложные кривые!
Регрессии бывают не только прямыми — можно строить криволинейные зависимости. Например, квадратичные. Для демонстрации я сгенерирую такие данные через NumPy.
Сначала создаю массив x:
Потом вычисляю y с квадратичной зависимостью.
Создаю DataFrame в Pandas — это как таблица, где есть столбцы «x» и «y». Назову его «df».
Посмотрю первые строки с помощью head:
Рисую диаграмму рассеяния в Seaborn — точно как для линейных данных:
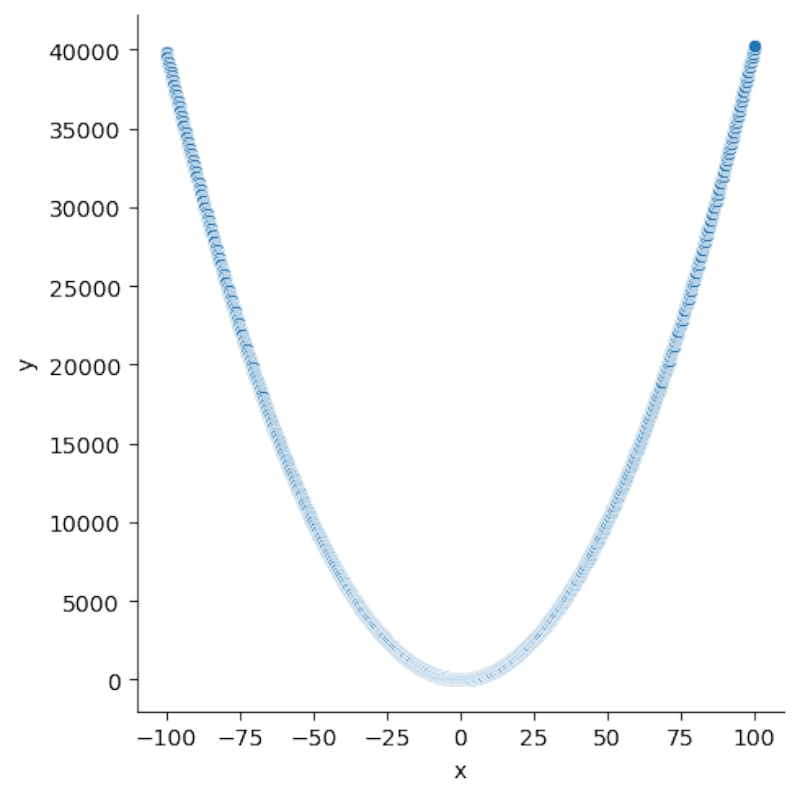
Получается классическая парабола, как на уроках алгебры (только теперь — в Python). Проверю, подойдет ли к данным кривая второго порядка: у regplot есть параметр order, ставлю 2.
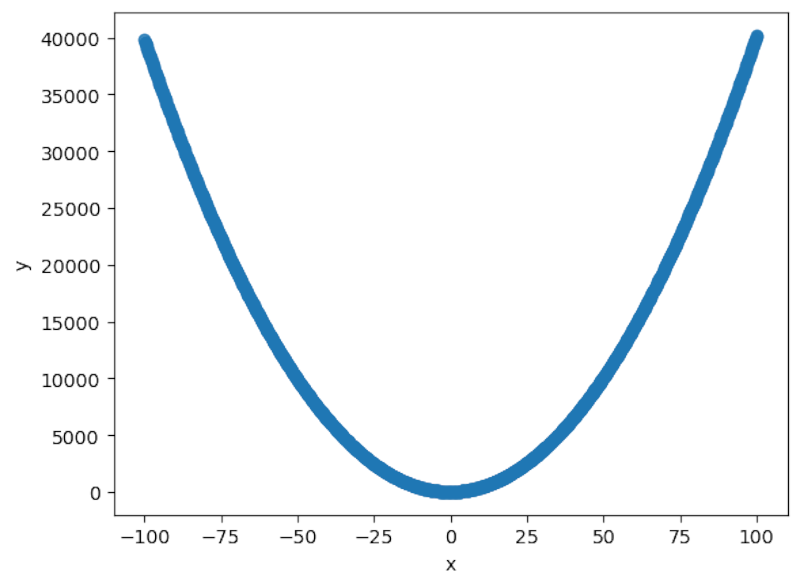
График отлично повторяет форму параболы.
Чтобы посчитать коэффициенты, добавляю в DataFrame новый столбец с x во второй степени:
Дальше, с помощью обычной линейной регрессии по x и x², строю квадратичную модель:
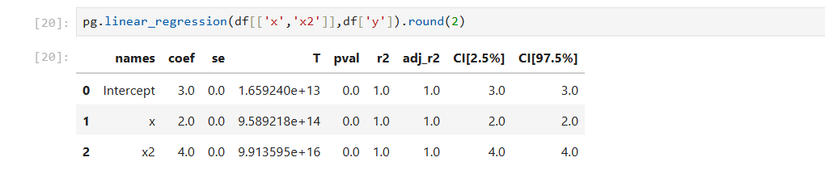
В этом учебном примере r² оказалось ровно 1 — в реальной жизни бывает намного скромнее.
Дальше собираю функцию для прогнозов по этой параболе:
Этот подход можно легко масштабировать на полиномы любой степени.
Логистическая регрессия: предсказываю «да» или «нет»
Когда нужно угадывать категории с двумя вариантами (например, человек курит или нет), использую логистическую регрессию.
Для наглядности опять строю график через Seaborn: беру данные о пассажирах «Титаника» и смотрю, как влияет стоимость билета на шанс выжить.
Просматриваю таблицу столбцов, как раньше с квадратичной зависимостью:

lmplot может рисовать логистическую кривую:
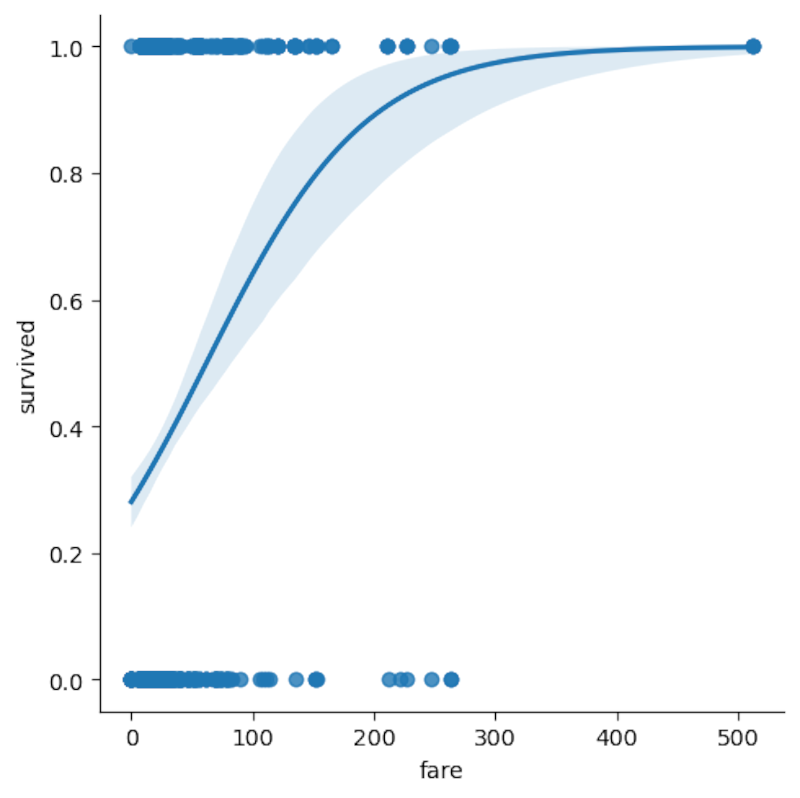
Кривая показывает, что шансы выжить действительно меняются в зависимости от цены билета. Поле «Survived» принимает значения 0 (нет) и 1 (да).
С помощью Pingouin проверяю, была ли цена билета серьезным фактором выживания — использую функцию logistic_regression:

Главное тут — p-value (столбец «pval» в таблице). Значение 0.0 показывает, что цена билета действительно влияла на шансы выжить на «Титанике».
Все эти примеры наглядно доказывают: Python невероятно удобен для анализа данных. То, на что вручную ушли бы недели, он делает за пару секунд. С помощью регрессии ты можешь не только находить глубокие законы в своих данных, но и строить действительно рабочие прогнозы!
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка — это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!
Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru






